Looped Attention¶
Looped attention iterates transformer blocks multiple times with learned iteration embeddings. The empirical result: 1.73x parameter efficiency through weight-sharing regularization.
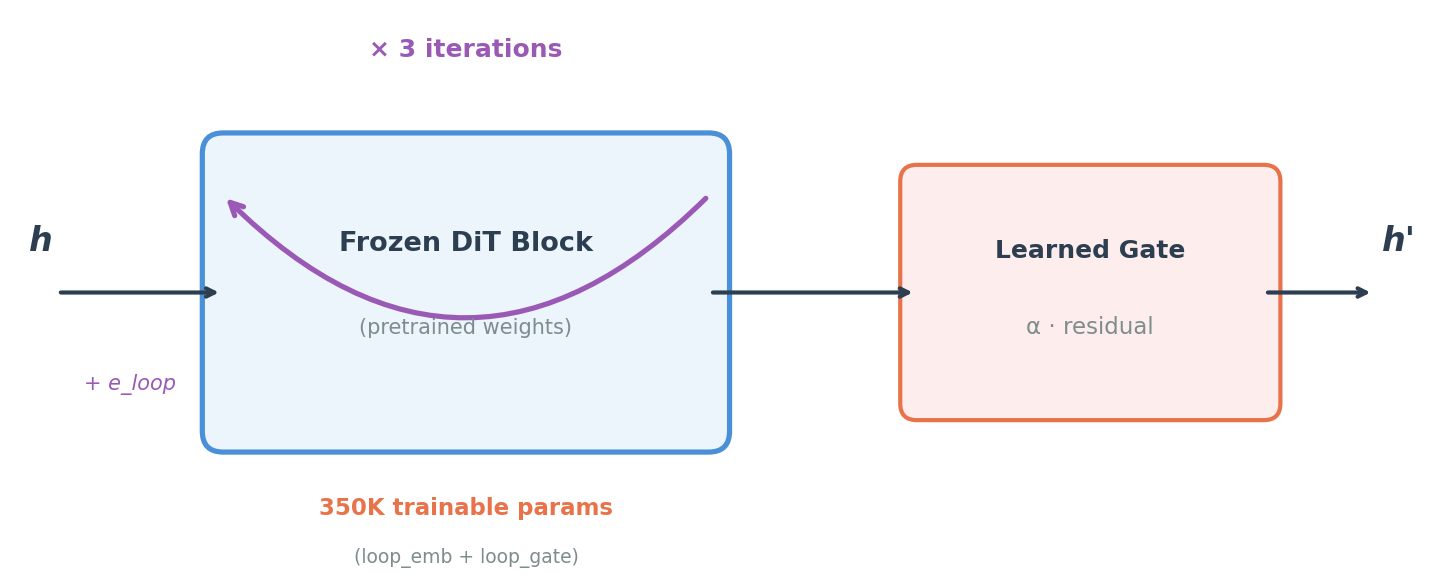
How it works¶
For each loop iteration l in [0, current_loops):
h_input = h + loop_emb[l] # learned perturbation
h_out = frozen_block(h_input, ...) # original pretrained forward
gate = sigmoid(loop_gate[l]) # scalar in (0, 1)
h = gate * h_out + (1 - gate) * h # gated residual mix
Zero-init safety¶
loop_embinitialized to zerosloop_gateinitialized to 0.0 → sigmoid(0) = 0.5
At init, the model behaves nearly identically to the pretrained backbone. No distribution shift. Safe to graft onto any frozen model.
Trainable parameters¶
Per block: (embed_dim + 1) × max_loops
CogVideoX-2B (d=1920, 3 loops, 30 blocks):
5,763 params/block × 30 = 172,890 + action_head ≈ 350K total
That's 0.02% of the 1.69B backbone.
Curriculum scheduling¶
scheduler = CurriculumScheduler(max_loops=3, total_steps=5000)
# Steps 0-1666: 1 loop
# Steps 1667-3333: 2 loops
# Steps 3334-5000: 3 loops
Why 3 loops?¶
From a 12-condition grid ablation (36 runs, $152 compute):
| Frozen (350K) | Half-frozen (3.7M) | Unfrozen (11.7M) | |
|---|---|---|---|
| 1 loop | 0.121 | 0.115 | 0.108 |
| 2 loops | 0.140 | 0.119 | 0.112 |
| 3 loops | 0.073 | 0.107 | 0.088 |
| 4 loops | 0.104 | 0.137 | 0.124 |
3 loops wins at every freeze level. 4 loops consistently regresses.
What looping is NOT¶
| Hypothesis | Result | Evidence |
|---|---|---|
| Iterative reasoning | Falsified | p=0.97, p>0.05, p>0.05 |
| Multi-modal binding | Falsified | 19% worse (p<0.0001) |
The benefit is weight-sharing regularization: fixed-point convergence (cosine sim 0.926 → 0.996), lower variance, better parameter efficiency. Not iterative reasoning.