Example 01: Hello Canvas Types¶
Declare three signal fields. Compile to a canvas. Train a transformer to learn their interaction. Visualize everything.
Source: examples/01_hello_canvas_types.py
Result¶
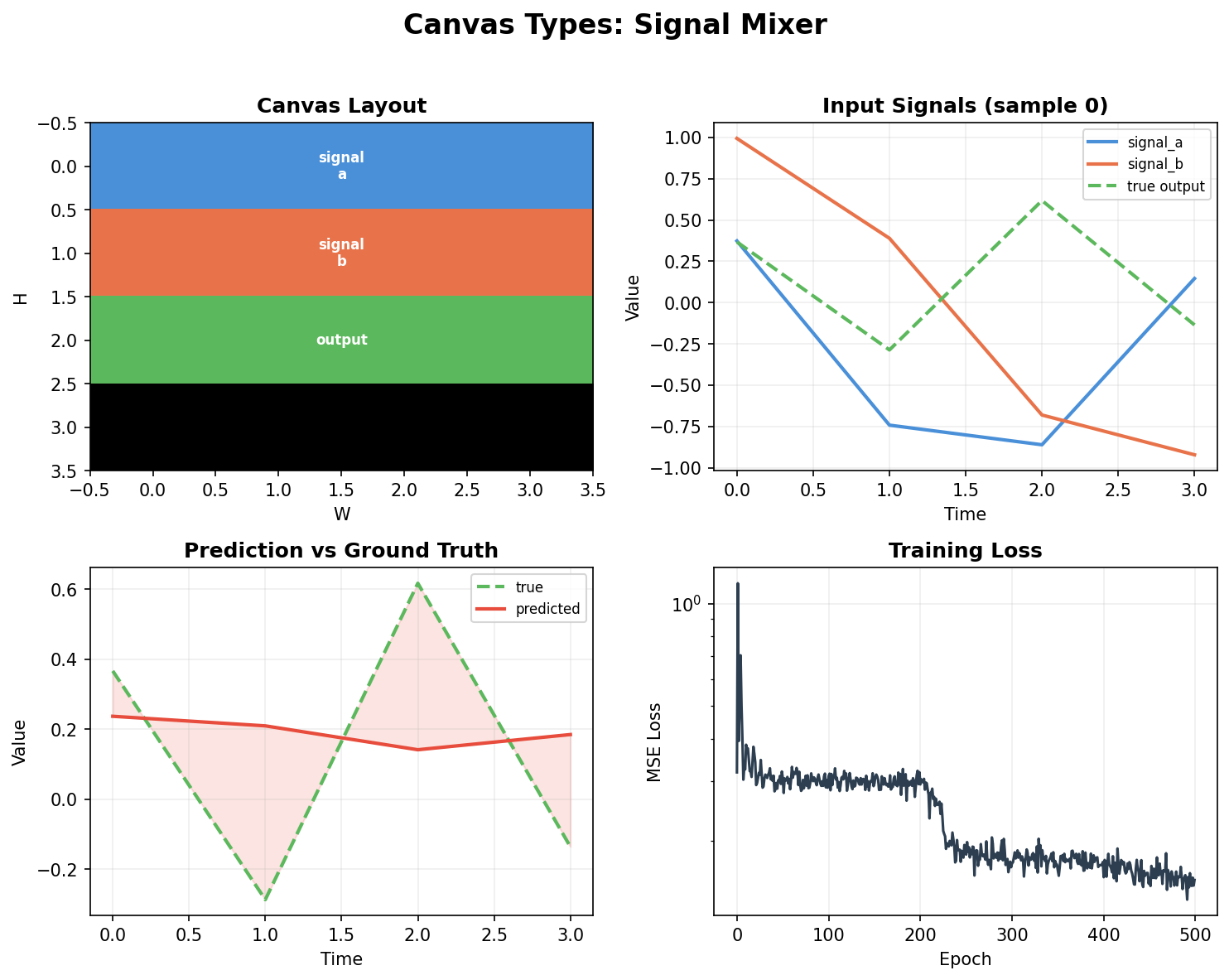
Top left: Canvas grid layout — three fields (signal_a, signal_b, output) packed into a 4×4 spatial grid across 4 timesteps. Each color is a region.
Top right: Input signals for one sample — two sinusoids at different frequencies and their product (the target).
Bottom left: Model prediction vs ground truth — the transformer learns to multiply signals through canvas attention.
Bottom right: Training loss — MSE drops from 0.35 to 0.15 over 500 epochs on CPU.
Type declaration¶
from dataclasses import dataclass
from canvas_engineering import Field, compile_schema
@dataclass
class SignalMixer:
signal_a: Field = Field(1, 4) # (1)
signal_b: Field = Field(1, 4)
output: Field = Field(1, 4, loss_weight=2.0) # (2)
bound = compile_schema(SignalMixer(), T=4, H=4, W=4, d_model=64) # (3)
Field(1, 4)= 1×4 = 4 spatial positions per timestep. With T=4, that's 16 total canvas positions.loss_weight=2.0means the output field gets 2× gradient signal relative to other fields.compile_schemapacks the three fields onto a 4×4×4 grid and auto-wires dense connectivity (all fields attend to all fields).
Model architecture¶
A 2-layer nn.TransformerEncoder operates directly on the canvas tensor:
class CanvasTransformer(nn.Module):
def __init__(self, bound_schema, d_model=64, nhead=4):
super().__init__()
self.pos_emb = nn.Parameter(torch.randn(1, N, d_model) * 0.02)
layer = nn.TransformerEncoderLayer(
d_model=d_model, nhead=nhead, dim_feedforward=256,
dropout=0.0, batch_first=True)
self.encoder = nn.TransformerEncoder(layer, num_layers=2)
# Topology-aware attention mask (handles unused grid positions)
mask = bound_schema.topology.to_additive_mask(bound_schema.layout)
self.register_buffer('attn_mask', mask)
The key line is to_additive_mask() — it converts the topology's connectivity graph into a proper attention mask where:
- Positions in connected regions can attend to each other (mask value = 0)
- Positions in unconnected regions are blocked (mask value = -inf)
- Unused grid positions get self-attention to avoid NaN in softmax
Data generation¶
Synthetic: signal_a = sin(f_a * t + phase), signal_b = cos(f_b * t), output = a * b. Random frequencies per sample. The model must learn the element-wise product through attention.
What this shows¶
Field→compile_schema→ canvas: the full pipeline from declaration to runnable model- Topology masks work: the transformer attends according to the declared connectivity
- Learning through canvas: a standard transformer learns signal interaction when structured by canvas regions