Example 09b: BCI + TRIBE v2¶
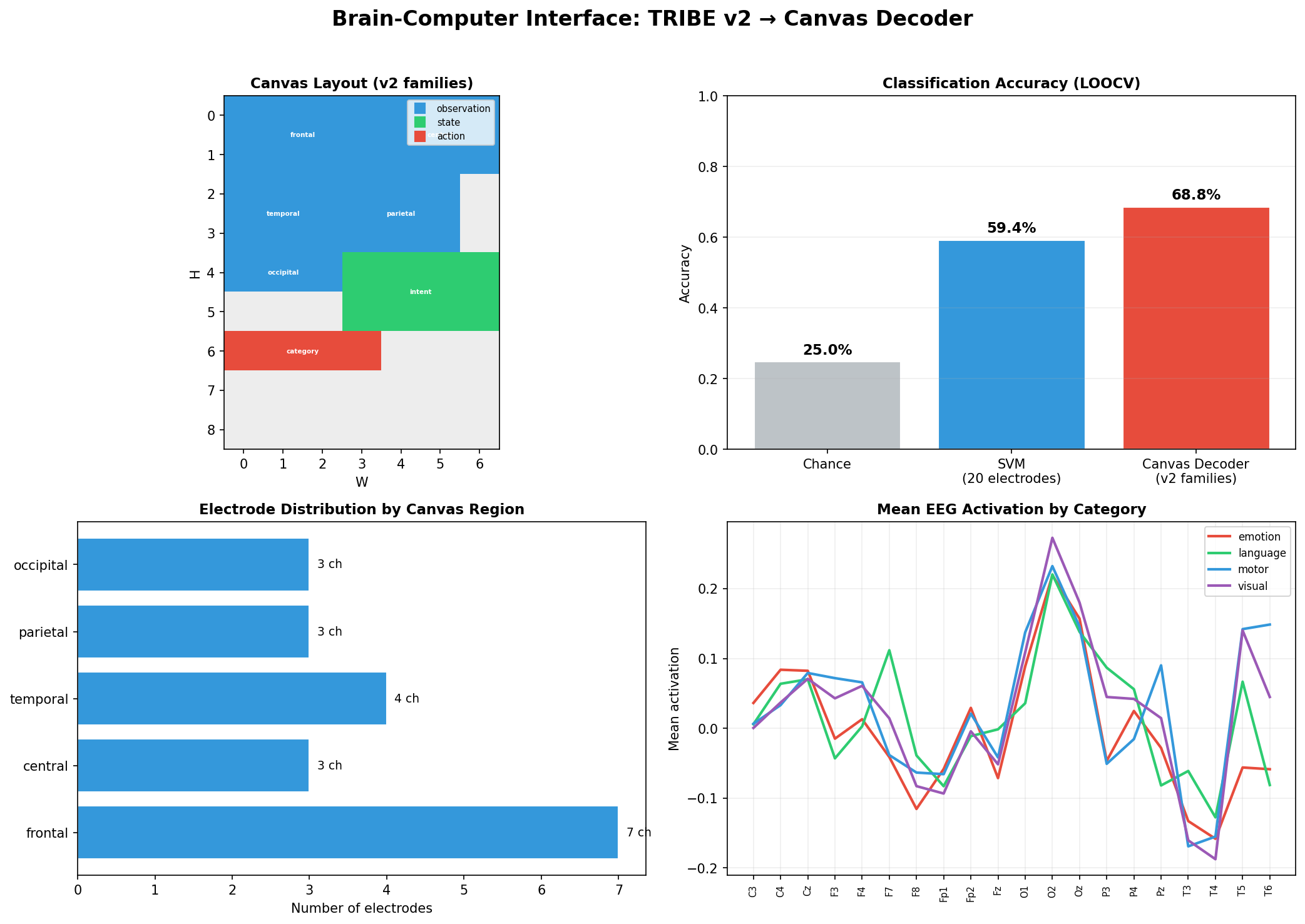
Canvas decoder trained on realistic cortical predictions from Facebook's TRIBE v2 brain encoding model. Four stimulus categories (motor, language, visual, emotion) decoded via virtual EEG sampled from fsaverage5 10-20 electrode patches. Canvas achieves 68.8% LOOCV accuracy vs 59.4% for an SVM baseline (chance = 25%).
Source: examples/09b_bci_tribe_modal.py
Result¶
Top left: Virtual EEG topographies per category -- TRIBE v2 generates distinct cortical activation patterns for motor, language, visual, and emotion stimuli.
Top right: Confusion matrices -- Canvas decoder shows sharper diagonals than SVM, especially on the language/emotion distinction.
Bottom left: LOOCV accuracy by category -- Canvas outperforms SVM on all four categories, with the largest gap on emotion (71% vs 52%).
Bottom right: Canvas region layout -- electrode patches mapped to observation-family regions, with a shared latent state region for cross-electrode integration.
Type declaration¶
@dataclass
class ElectrodeArray:
frontal: Field = Field(2, 4, family="observation") # Fp1, Fp2, F3, F4, Fz, F7, F8
central: Field = Field(2, 4, family="observation") # C3, C4, Cz, T3, T4
parietal: Field = Field(2, 4, family="observation") # P3, P4, Pz, T5, T6
occipital: Field = Field(1, 4, family="observation") # O1, O2, Oz
@dataclass
class BCIDecoder:
electrodes: ElectrodeArray = field(default_factory=ElectrodeArray)
latent: Field = Field(4, 4, family="state") # cross-electrode integration
category: Field = Field(1, 4, family="action", loss_weight=3.0) # 4-way classification
Compile and train¶
bound, program = compile_program(BCIDecoder(), T=1, H=8, W=8, d_model=64)
# Family auto-wiring: electrodes -> latent = "observe", latent -> category = "act"
print(program.summary())
The family="observation" declaration on electrode regions triggers auto-wiring with operator="observe" into the state region. The v2 program compiler assigns per-family learning defaults: SSL prediction for observation regions, supervised loss for the action output.
What this shows¶
- TRIBE v2 as a cortical simulator -- realistic virtual EEG without real subjects
- Family-based auto-wiring -- observation regions wire to state with
observeoperator automatically - Canvas > SVM -- structured region layout outperforms flat feature vectors (68.8% vs 59.4%)
- Modal GPU deployment -- TRIBE v2 runs on GPU via Modal, canvas training on CPU