canvas-engineering
A type system for multimodal latent dynamics that turns video diffusion models into structured world-modeling substrates.
canvas-engineering is the clearest expression on this site of a recurring idea in my work: models get easier to steer when their internal spaces are given structure instead of being treated as undifferentiated tensors.
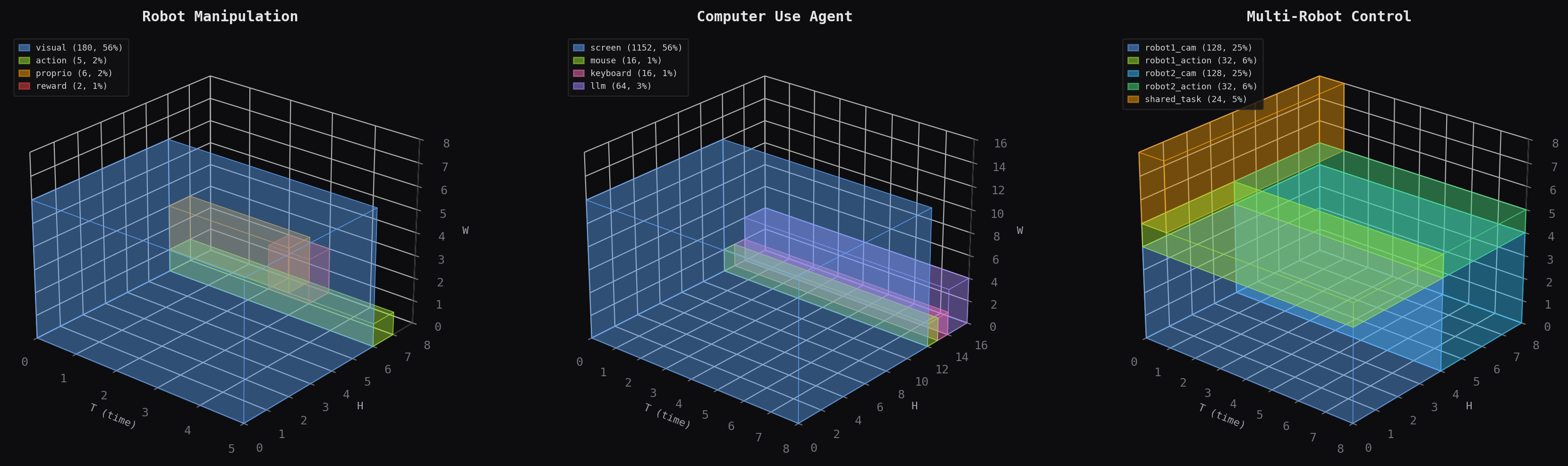
The core move is simple. Instead of asking a diffusion transformer to discover on its own which latent positions should represent vision, action, reward, proprioception, or thought, you declare that layout directly. The layout becomes the schema, the topology becomes the compute graph, and the resulting model behaves more like a typed program than a bag of embeddings.
That view matters because it makes multimodal world models compositional. Different regions can run at different temporal frequencies, participate in different losses, and connect through different attention operations, while still living on the same spatiotemporal canvas.
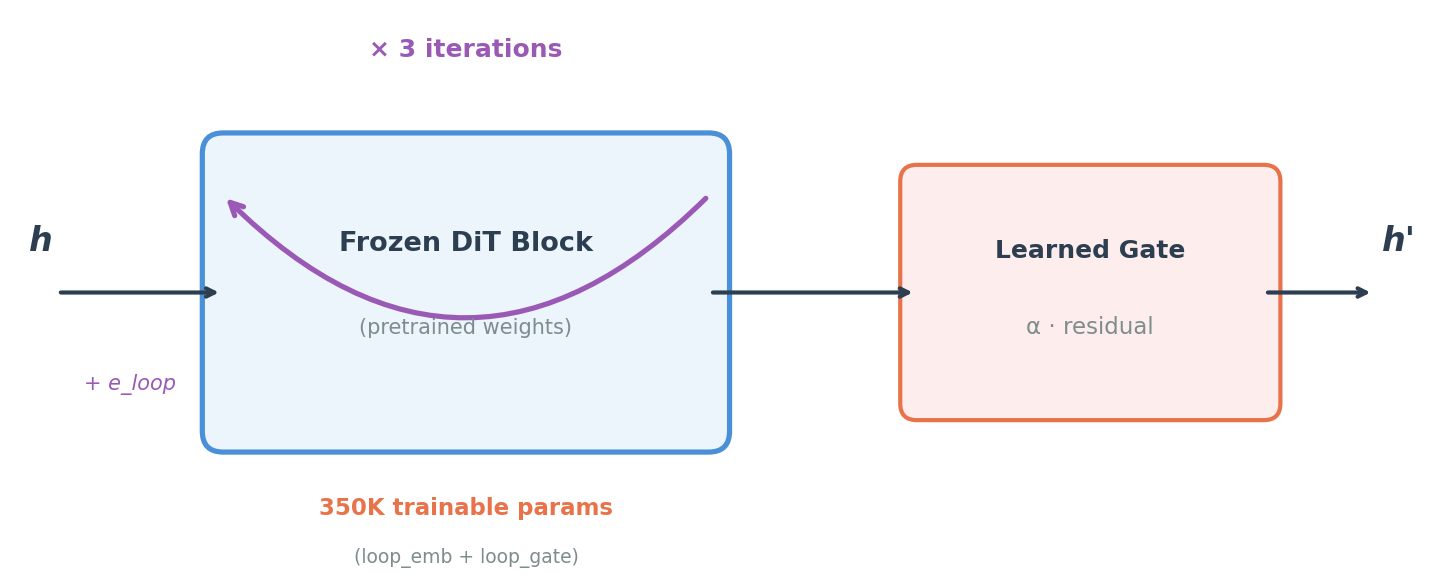
The second idea in the project is looped attention: reusing transformer blocks across multiple learned iterations. In the current writeup, that is framed less as “reasoning depth” and more as a weight-sharing regularizer that makes frozen backbones substantially more parameter-efficient. That pairing is what makes the project interesting to me: one part is about giving latent space semantics, and the other is about making the compute over that space cheaper and more reusable.
The published docs at jacobfv.github.io/canvas-engineering also make clear that this is meant to be a real design language, not just a one-off research note. The library has concepts for RegionSpec, CanvasTopology, semantic types, carriers, clocks, and executable examples spanning control, agentic computer use, and brain-computer-interface settings.